The feasibility of a whole-cell model of the human platelet
21 May 2026
Build code from source data — start with the data
Start with the published data (usually PDF, sometimes CSV).
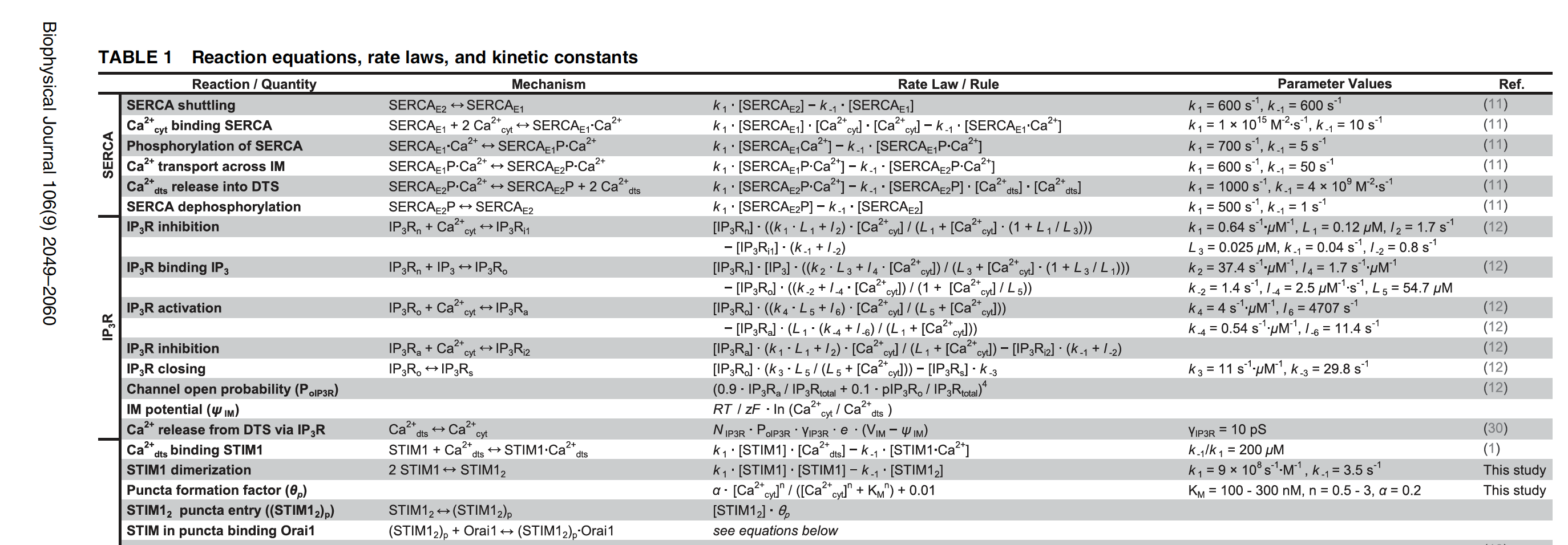
Just a small excerpt.
Build code from source data — AI extraction
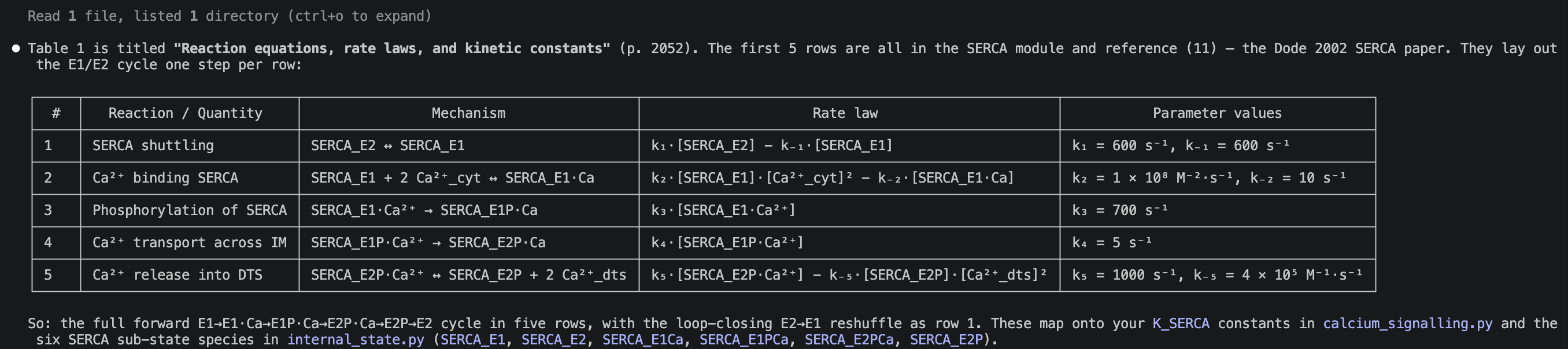
Ask AI to extract — get it to tell you what it’s doing to sanity check (but it is very good at this).
E.g. I asked: “Please read Dolan and Diamond 2014 and tell me what the first 5 lines of table 1 show.”
Simply not feasible to do this by hand at large scale; AI could process 100s of papers in a day. The only challenge is verification, but this is also amenable to AI assistance.
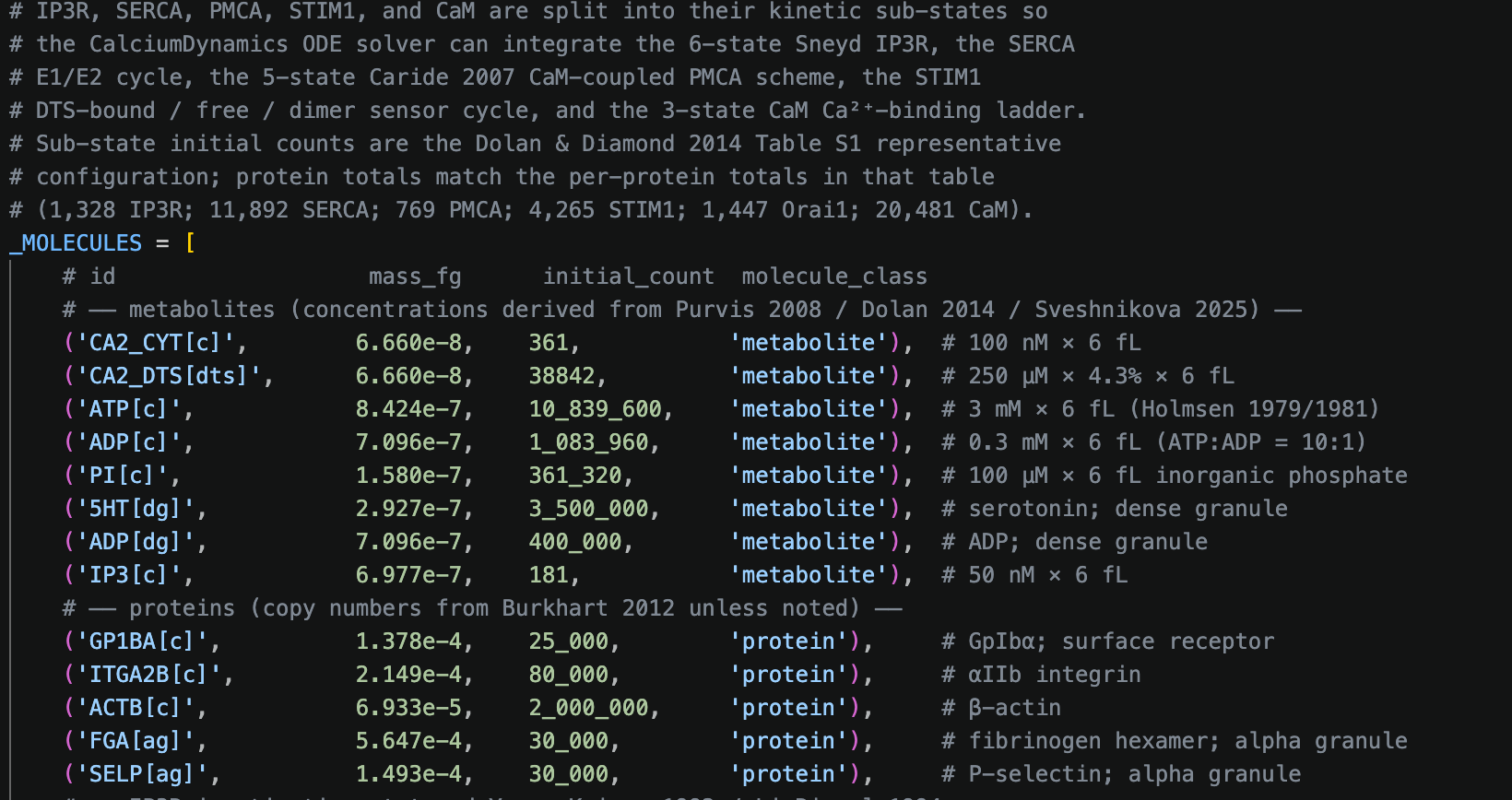
Build code from source data — AI writes the code
Then get AI to build the code, using the wcEcoli code as a template.
The code works well, the architecture is not perfect — needs some work to make it more usable for future expansion — but it’s an excellent start.
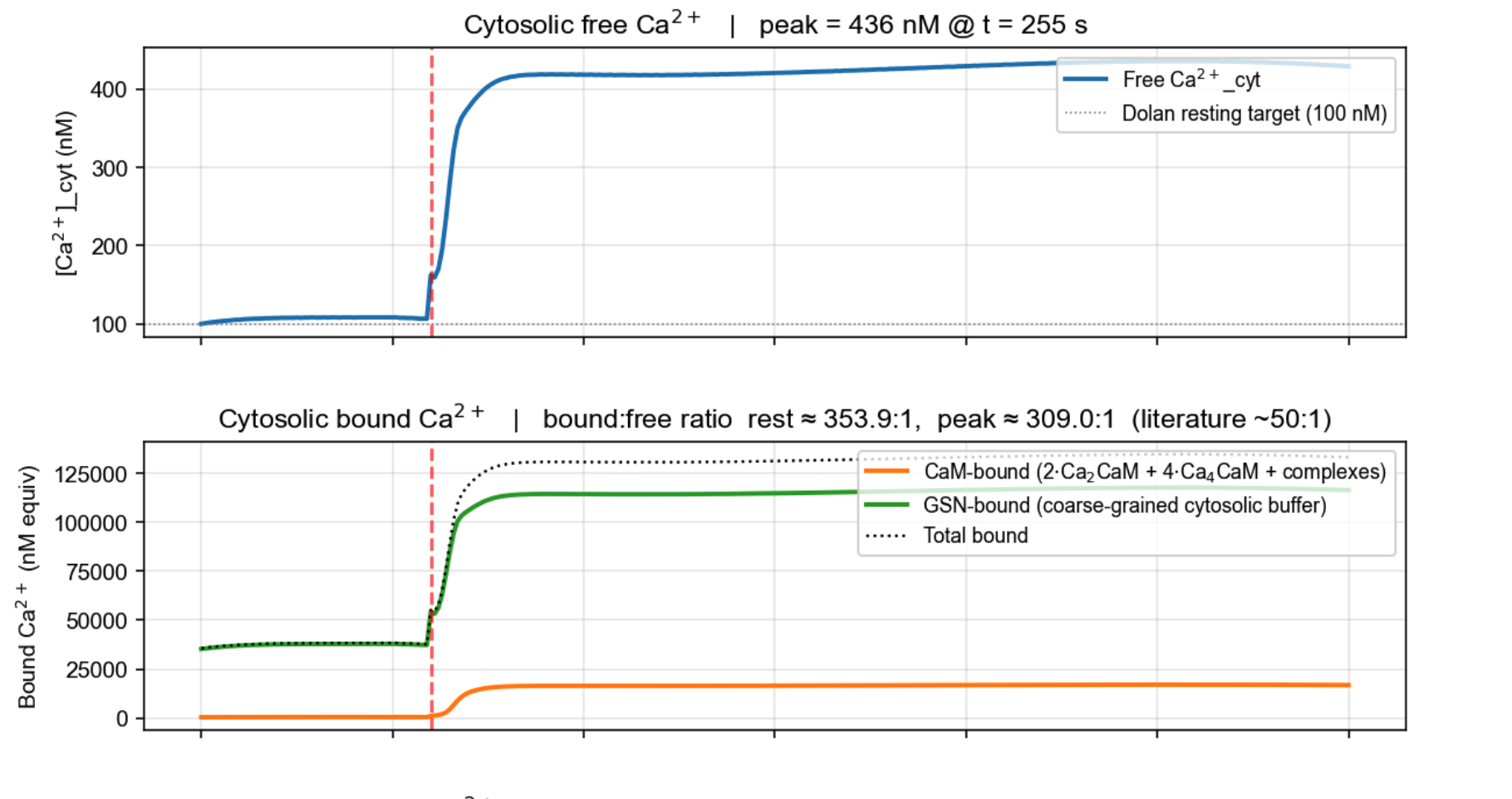
What did I build? (so far)
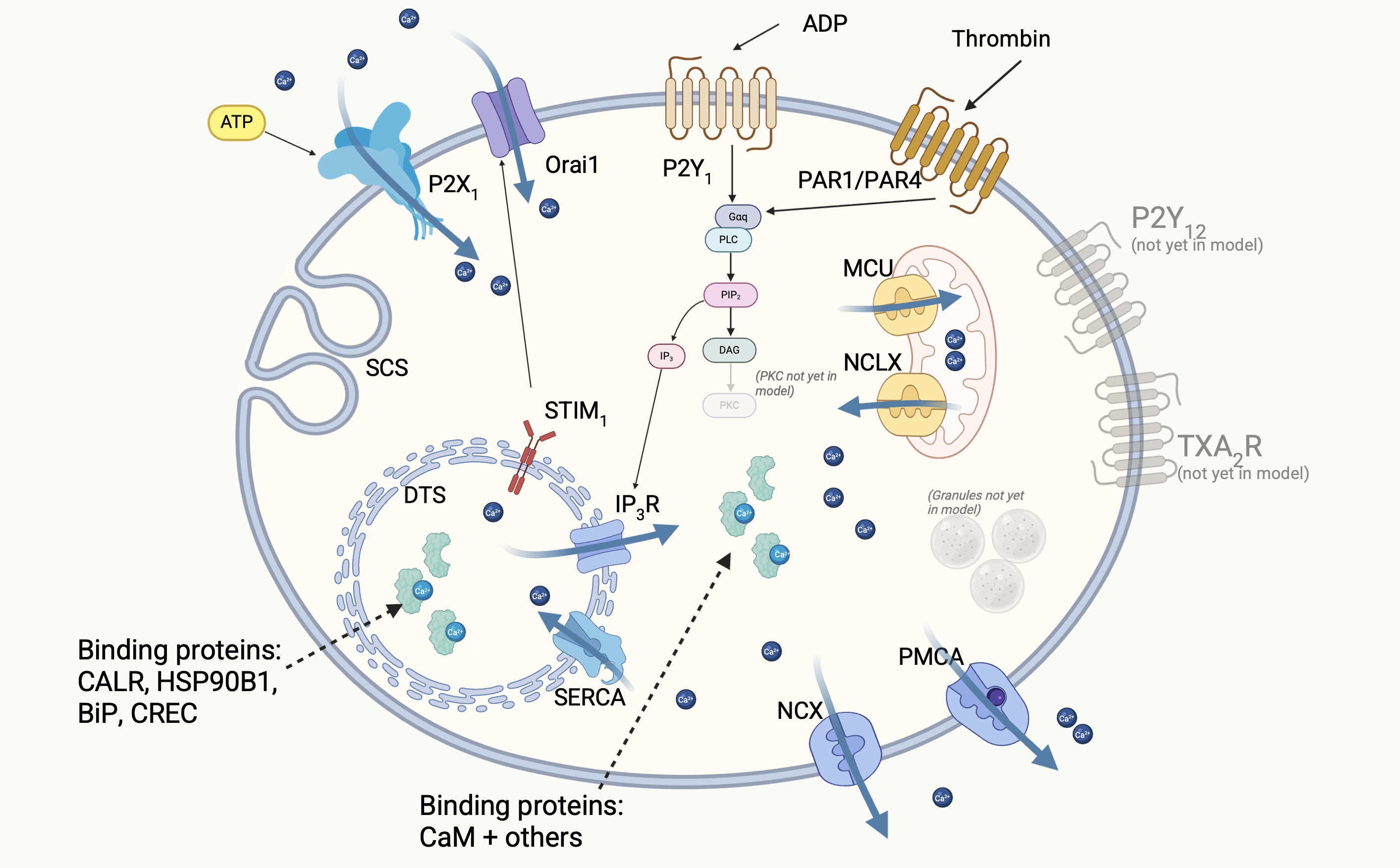
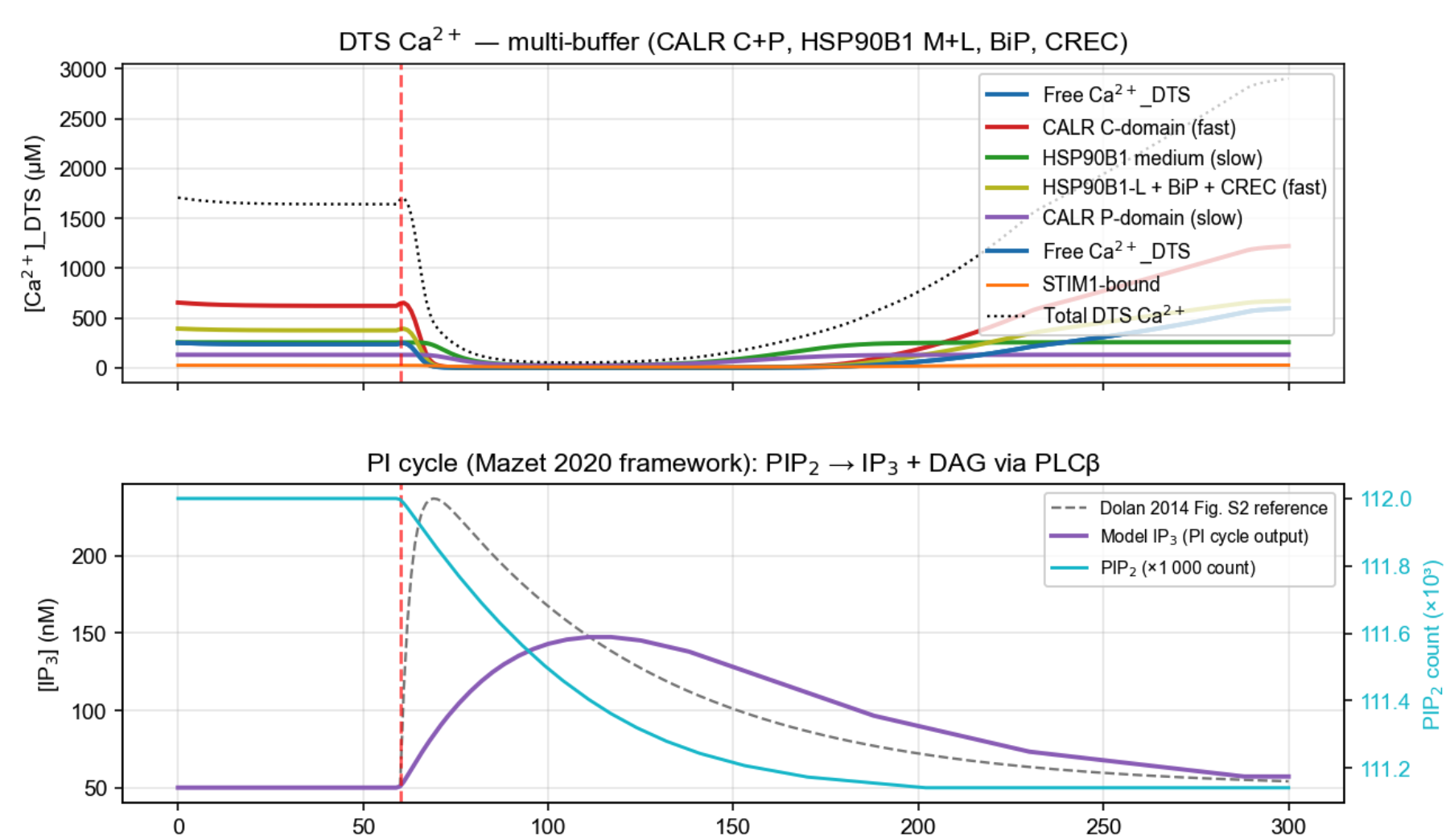
Model stimulated with ADP / thrombin — cytosolic Ca²⁺
Model stimulated with ADP / thrombin — DTS Ca²⁺